Khoa CNTT (UET FIT) trân trọng giới thiệu bài báo:
“Leveraging local and global relationships for corrupted label detection”
được thực hiện bởi các sinh viên tài năng K67, Lâm Nguyễn Duy Phong, Nguyễn Hà Linh, Đặng Đào Xuân Trúc, Trần Văn Sơn, Lê Minh Đức, cùng các thầy/cô TS. Nguyễn Thu Trang, TS. Nguyễn Văn Sơn, và PGS. TS. Võ Đình Hiếu.
Nghiên cứu này được công bố trên tạp chí Future Generation Computer Systems (Q1, IF 6.2).
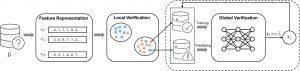
Chất lượng dữ liệu huấn luyện đóng vai trò rất quan trọng trong hiệu suất của các mô hình học máy và deep learning. Tuy nhiên, thực tế cho thấy các bộ dữ liệu thường chứa một tỷ lệ nhãn lỗi đáng kể (từ 8% đến 38,5%), ảnh hưởng không nhỏ đến độ chính xác của mô hình. Để giải quyết vấn đề này, nhóm nghiên cứu đã phát triển phương pháp Cola – một giải pháp dựa trên việc khai thác mối quan hệ cục bộ và toàn cục trong dữ liệu nhằm phát hiện nhãn lỗi một cách hiệu quả.
– Khai thác mối quan hệ cục bộ và toàn cục: Cola dựa trên giả định rằng các mẫu dữ liệu tương tự thường có cùng nhãn, từ đó giúp phân biệt được nhãn đúng và nhãn lỗi.
– Hiệu quả được kiểm chứng: Qua các thí nghiệm trên các bộ dữ liệu hình ảnh, văn bản và âm thanh, so với các giải pháp tốt nhất hiện nay, Cola đã cải thiện F1-score từ 8% đến 21% trong việc phát hiện các loại nhãn lỗi khác nhau, cải thiện tới 80% với dữ liệu hình ảnh và trung bình 17% với dữ liệu văn bản. Tỉ lệ phát hiện lỗi chính xác của Cola lên tới 91%.
– Tốc độ và độ chính xác vượt trội: So với một số mô hình tiên tiến hiện nay, như Llama3, Cola cho thấy khả năng tăng độ chính xác lên đến 112% và giảm thời gian xử lý gần 300 lần.
Phương pháp này hứa hẹn sẽ góp phần cải thiện chất lượng dữ liệu huấn luyện trong nhiều ứng dụng như nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên và giám sát dữ liệu lớn, từ đó nâng cao hiệu quả cho các hệ thống AI.
Hãy cùng chúc mừng nhóm tác giả với bước tiến quan trọng này trong việc cải thiện chất lượng dữ liệu và nâng cao hiệu suất của các hệ thống AI!